Advisor 패턴
LLM 호출 전후에 요청/응답을 가로채어 변환하는 인터셉터 패턴
-> 로깅, 보안 필터링, 응답 제한, 대화 기억 등 다양한 횡단 관심사(Cross-Cutting-Concern)를 처리
flowchart LR
A["사용자 요청"] --> B["Advisor 1
전처리"]
B --> C["Advisor 2
전처리"]
C --> D["Advisor 3
전처리"]
D --> E["🧠 LLM 호출"]
E --> F["Advisor 3
후처리"]
F --> G["Advisor 2
후처리"]
G --> H["Advisor 1
후처리"]
H --> I["사용자 응답"]
특징
- 실행 순서 : order값이 작을수록 먼저 실행됨(HIGHEST_PRECEDENCE -> LOWEST_PRECEDENCE)
- ChatClient 생성 시 생성하여 주입해 줌
예시

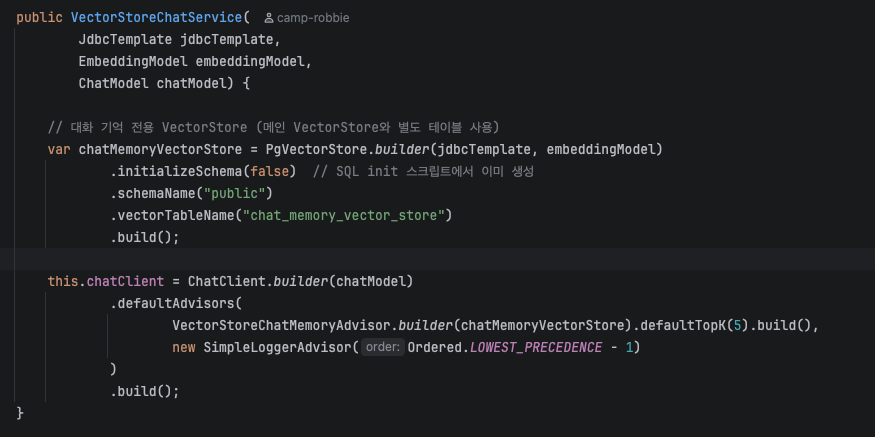
ChatService에서 chatClient 생성 시 defaultAdvisors()에 SimpleLogerAdvisor를 공통적으로 담아주었음


Advisor 인터페이스
Advisor는 동기/비동기 두 가지 인터페이스가 있음
| 인터페이스 | 메서드 | 용도 |
| CallAdvisor | adviseCall() | 동기 호출 시 전/후처리 |
| StreamAdvisor | adviseStream() | 스트리밍 호출 시 전/후처리 |
classDiagram
class CallAdvisor {
<>
+adviseCall(ChatClientRequest, CallAdvisorChain) ChatClientResponse
+getName() String
+getOrder() int
}
class StreamAdvisor {
<>
+adviseStream(ChatClientRequest, StreamAdvisorChain) Flux~ChatClientResponse~
+getName() String
+getOrder() int
}
class SimpleLoggerAdvisor {
내장: 요청/응답 로깅
}
class SafeGuardAdvisor {
내장: 민감한 단어 필터링
}
class RequestTimingAdvisor {
커스텀: 요청 시간 측정
}
class MaxCharLengthAdvisor {
커스텀: 응답 문자 수 제한
}
CallAdvisor <|.. SimpleLoggerAdvisor
CallAdvisor <|.. SafeGuardAdvisor
CallAdvisor <|.. RequestTimingAdvisor
CallAdvisor <|.. MaxCharLengthAdvisor
StreamAdvisor <|.. RequestTimingAdvisor
StreamAdvisor <|.. MaxCharLengthAdvisor
Advisor 유형
내장 Adivisor
- SimpleLoggerAdvisor : 요청과 응답을 DEBUG로그로 출력하는 가장 기본적인 Advisor
- 보통 order를 LOWEST_PRECEDENCE-1로 설정하여 가장 마지막에 실행되도록 함 : 다른 Advisor들이 변환한 최종 요청/응답을 로깅할 수 있음
- SafeGuardAdvisor : 민감한 단어가 포함된 요청을 차단하는 보안 Advisor
- 민감 키워드가 감지되면 LLM을 호출하지 않고 즉시 거부 메시지를 반환 -> API 비용 절약에 기여

대화 기억 관련 Advisor
- MessageChatMemoryAdvisor: 대화 기억을 메시지 모음(UserMessage + AssistantMessage)으로 프롬프트에 추가.
- LLM이 대화 내 역할(user/assistant)을 정확히 구분할 수 있어 더 정확한 대화가 가능
- 실제 멀티턴 대화에서 LLM에 보내는 메시지 구조 예시
[
{ "role": "user", "content": "스프링 AI가 뭐야?" },
{ "role": "assistant", "content": "Spring AI는 LLM 통합 프레임워크입니다." },
{ "role": "user", "content": "그럼 Advisor는?" }
]- PromptChatMemoryAdvisor : 이전 대화를 텍스트 형태로 시스템 메시지에 포함시킴.
- 메시지 역할 구분 없이 하나의 텍스트 블록으로 전달
- VectorStoreChatMemoryAdvisor : 현재 대화와 의미적으로 유사한 이전 대화만 검색하여 프롬프트에 추가
- VectorStoreChatMemoryAdvisor 동작 방식
undefined
커스텀 Advisor 만들기
예시 : RequestTimingAdvisor : LLM 요청의 소요 시간 측정
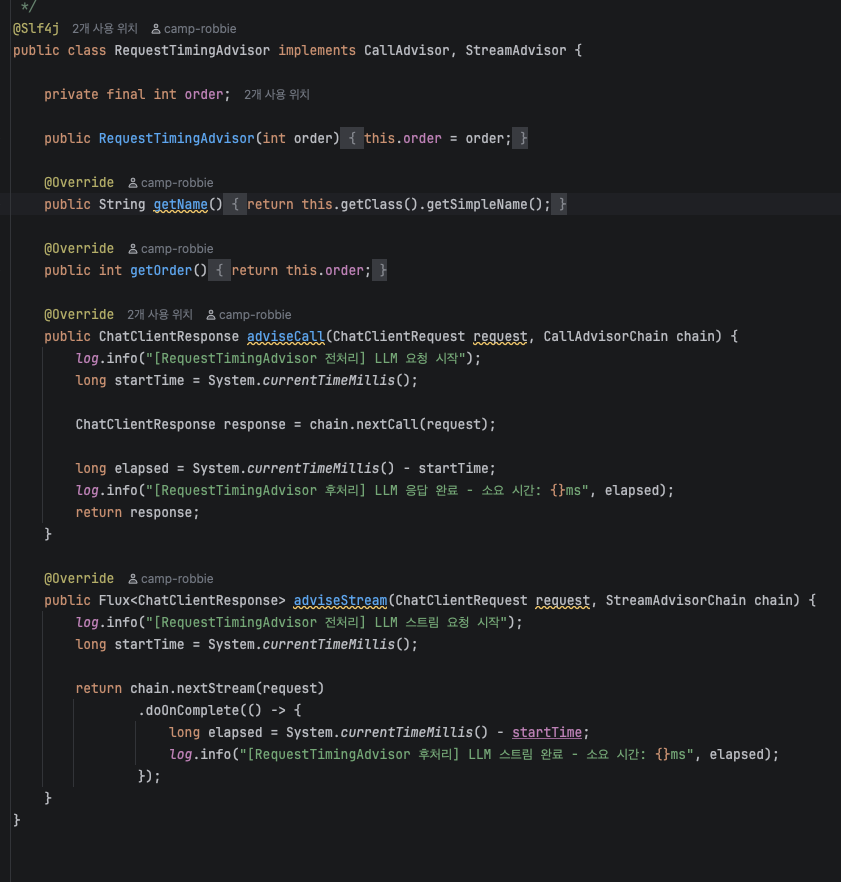
특징
- chain.nextCall() : 다음 Advisor 또는 LLM을 호출한다.
- CallAdvisor + StreamAdvisor 동시 구현 : call()과 stream() 양쪽 호출 모두 지원한다.
- doOnComplete() : 모든 청크가 수신된 후 최종 전달 시간을 기록한다.
예시 : MaxCharLengthAdvisor : 응답 문자 수 제한

특징
- augmentMessages() 메서드로 시스템 메시지와 사용자 메시지에 제한 지시문을 이중으로 추가
flowchart TD
A["원본 요청
User: 'Spring AI를 설명해줘'"] --> B["MaxCharLengthAdvisor"]
B --> C["1. SystemMessage 추가
'반드시 200자 이내로 답변하세요'"]
C --> D["2. UserMessage 강화
'Spring AI를 설명해줘
[주의: 200자 이내로 답변해주세요]'"]
D --> E["변환된 요청으로 다음 Advisor/LLM 호출"]
Context를 통한 데이터 전달
Contoller -> Service -> Advisor 간 데이터 (예 : 최대 응답 길이 제한 기준 숫자)를 전달하는 방식
advisorSpec.param()으로 전달한 값은 request.context()를 통해 Advisor 내부에서 읽을 수 있게 됨.

flowchart LR
A["Controller
maxCharLength: 150"] --> B["Service
advisorSpec.param()"]
B --> C["request.context()"]
C --> D["MaxCharLengthAdvisor
charLimit = 150"]
'Career Development > AI' 카테고리의 다른 글
| 하네스 엔지니어링 (0) | 2026.05.26 |
|---|---|
| 운동 관리 앱 만들기[Levio] DAY 1 (0) | 2026.05.16 |
| 클로드는 업무 운영 시스템이다 (0) | 2026.05.16 |
| [Spring AI] Chat Memory(대화 기억) (0) | 2026.04.02 |